
Left: Original image containing multiple windows Right: Overlay of detected rectangles.
Apple’s Vision framework provides a useful set of tools for common computer vision tasks including face detection, object classification, barcode scanning, and rectangle detection. In this post we will discuss why you should consider rectangle detection over fancier methods, briefly go over setting up vision requests, and then take a semi-deep dive into rectangle detection using VNDetectRectanglesRequest. My hope is after reading this post you will feel comfortable setting up rectangle detection in your own projects and have an intuition on how to adjust the request parameters to get the output you are interested in.
This post has an accompanying MacOS XCode project available on GitHub. Feel free to download and experiment!
Why rectangle detection?
Rectangular shapes are everywhere in our visual world. Indoor structures such as doors, hallways, and windows are rectangular. Objects like pictures, tabletops, letters, books, envelopes, and signs…yep. All rectangles. So it should come as no surprise that being able to detect rectangular-shaped things in an image is useful. In fact, researchers have actually been working on rectangle and other shape detection methods since at least the 80s. But it’s 2020 and a lot has changed. Machine learning has seen a resurgence of neural networks over the last decade and we now have convolutional neural networks (CNNs) and systems such as YOLO that can perform object detection for roughly 90 classes of objects all at once on video streams. So you might be asking yourself, why use 40 year old technology? Shouldn’t I instead focus my efforts on using machine learning and training a classifier/detector for my fancy new task?
In short, you could, but Dr. Ian Malcom might scold you and say you should have stopped to think if you should. First off, CNNs and neural networks in general, are computationally expensive often containing millions of parameters. So if you want to run your task on a mobile device you will be causing some serous battery drain. Second, training neural networks often requires hundreds or thousands of labeled examples to ensure the model will generalize well and not become overfit to the training data. Conventional rectangle detection may not seem glamorous, but it actually has a number of advantages over neural networks. Rectangle detection is a generalized method that can be applied to any image, requires zero training data, and zero training time. Rectangle detection is also both faster and less computationally expensive than a typical CNN. So now that I have convinced you, let’s go take a look at setting up requests in Vision.

Setting up requests in Vision
Performing requests on still images in Vision can be summarized as follows: 1. Create a request handler initialized with your image of interest, 2. Create a vision request (e.g. VNDetectRectanglesRequest) specifying what you want Vision to do, 3. Run the perform method on your request handler to initiate the request. The whole process generally looks something like this:
let requestHandler = VNImageRequestHandler(url: inputImageURL)
let request = VNDetectRectanglesRequest { request, error in
self.completedVisionRequest(request, error: error)
}
// perform additional request configuration
request.usesCPUOnly = false //allow Vision to utilize the GPU
DispatchQueue.global().async {
do {
try requestHandler.perform([request])
} catch {
print("Error: Rectangle detection failed - vision request failed.")
}
}As you can see, there isn’t much too it, but let me point out a few things not directly apparent from this code snippet. First let’s talk about image request handlers. In this example I have created a requestHandler that uses a URL to specify an image, but VNImageRequestHandler actually has a number of initializer methods that allow for requests based on CGImages, CIImages, etc. For example, if you wanted to run your Vision request off of the camera feed from an active augmented reality session in iOS, you might initialize your handler from your ARSCNView like so:
let pixelBuffer = sceneView?.session.currentFrame?.capturedImage
let handler = VNImageRequestHandler(cvPixelBuffer: pixelBuffer, orientation: .up)Next, let’s take a look at the request. Notice the trailing closure? All of the VNRequest types including VNDetectRectanglesRequest have an optional completionHandler you can use to process the results of your request and handle errors if they pop up. Here, I am simply passing the request and error off to another function completedVisionRequest.
Now let’s look at options. Each subclass of VNRequest has options specific to that request type that you can set. For example VNDetectRectanglesRequest has an option .maximumObservations, which dictates how many rectangle observations to return. There are also options inherent to all requests. One of them is .usesCPUOnly. If you are doing a lot of rendering or, for example, classifying images using a neural network, it may be useful to set this option to true so the GPU doesn’t get overwhelmed.
The last point I wanted to make is that the perform([request]) actually takes an array of VNRequest objects, so if you wanted to ,for example, perform both barcode scanning and rectangle detection on the same image, you may certainly do so.
Processing Vision Request Results
When a VNRequest is completed the completionHandler that was supplied during the initial setup is called. In the example above this was:
let request = VNDetectRectanglesRequest { request, error in
self.completedVisionRequest(request, error: error)
}In this case, the function completedVisionRequest might look something like:
func completedVisionRequest(_ request: VNRequest?, error: Error?) {
// Only proceed if a rectangular image was detected.
guard let rectangles = request?.results as? [VNRectangleObservation] else {
guard let error = error else { return }
print("Error: Rectangle detection failed - Vision request returned an error. \(error.localizedDescription)")
return
}
// do stuff with your rectangles
for rectangle in rectangles {
print(rectangle.boundingBox)
}Each request object has an optional array .results of type [Any]?, so the first step in processing the results is to cast the array as the expected result type. Here, since we are doing rectangle detection, we are expecting an array of VNRectangleObservation. Once this is done, you are ready to digest the results in any way that you like. In the sample above I am simply printing out the bounding boxes for each rectangle. In the sample app that accompanies this post, detected rectangles are redrawn over the original image.

Exploring VNDetectRectangleParameters
The VNDetectRectanglesRequest class has a number of parameters that can you can adjust to ensure the algorithm returns the results you are interested in. Take a quick look at the table I have provided. We will go over each setting in turn and explore how changing that setting affects request output.
| Name | Type | Range | Default |
|---|---|---|---|
| .maximumObservations | Int | [0...] | 1 |
| .minimumAspectRatio | Float | [0.0...1.0] | 0.5 |
| .maximumAspectRatio | Float | [0.0...1.0] | 0.5 |
| .minimumSize | Float | [0.0...1.0] | 0.2 |
| .quadratureTolerance | Float | [0.0, 45.0] | 30.0 |
| .minimumConfidence | Float | [0.0...1.0] | 0.0 |
.maximumObservations
As the name implies .maximumObservations specifies how many rectangle observations you’d like the request to return. The default setting of 1 only gets you a single observation, but you can get a list of all possible rectangles by setting .maximumObservationsto zero. What might not be so obvious is what rectangles get returned when .maximumObservations is less than the number of rectangles in the image. You may need to experiment a bit, but as far as I can tell the algorithm returns rectangles in the order that it finds them, stopping when either it completes the search or the observation limit is reached.
.minimumAspectRatio and .maximumAspectRatio

Two images treated by the Vision Framework as having an aspect ratio 9:16
The next two parameters deal with the aspect ratio of rectangles in an image. As you may recall when looking at the specs for a new TV or camera, the aspect ratio of an image is the ratio width : height. Digital movie formats are delivered as 4:3 or now more commonly 16:9. Here, Apple’s docs define the aspect ratio slightly differently as the ratio of shorter : longer. This difference is subtle, but important. A long short rectangle is treated the same as a tall skinny rectangle.
Now let’s take a look at a sample image containing a variety of aspect ratios and experiment with the min and max aspect ratio parameters (for all experiments, assume we set .maximumObservations to 0).
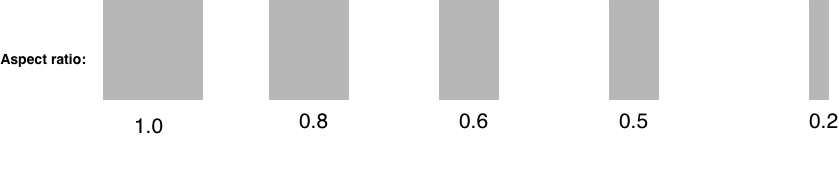
Our sample image has five rectangles in a range of aspect ratios from 1.0 to 0.2. The default parameters for .minimumAspectRatio and .maximumAspectRatio are both set to 0.5. How many rectangles do you think we will get with the default settings? If you guessed 1, good thought, but actually we need to adjust one of the parameters either up or down to get results. Here is the output if we set .minimumAspectRatio to 0.4.

And if we open the range to cover all aspect ratios? Let’s change .minimumAspectRatio to 0.0 and .maximumAspectRatio to 1.0.

We got almost all of them, but what about the 0.2 aspect ratio box? Well, it turns out the min and max parameters are behaving as they should, but the default for minimum rectangle size is preventing the smallest rectangle from showing up…which is a great segue for talking about the size parameter!
.minimumSize
The description for .minimumSize in the official docs weren’t entirely clear to me on my first read.
…the minimum size of the rectangle to be detected, as a proportion of the smallest dimension.
What do they mean by the size of the rectangle? Is size the area, the width, or height? And what is the smallest dimension referring to? It turns out that the proportion being referred to is the length of a rectangle’s shortest side compared to the smallest dimension (width or height) of the image. Let’s look at an example to illustrate.
Here is an image that is 800px by 1000px containing a single rectangle that is 400px by 750px. What do you think .minimumSize should be set to so that the rectangle is returned by the request?

If you said 0.5 or less you are correct! The smallest dimension of the rectangle is 400px and the smallest dimension of the image is 800px. 400/800 = 0.5. Before moving on, let me leave you with a visual aid that might be useful when trying to figure out what setting to pick in your own work.

.quadratureTolerance
When objects like a table are viewed from the top down the adjoining sides form 90° angles making a perfect rectangle. But unless you are a bat, you probably look at your table from the side while standing on the ground. From this perspective, the angles are skewed and appear to deviate from 90°, which is a common phenomenon for many rectangular objects in real-world images. To accommodate, VNDetectRectanglesRequest has a .quadratureTolerance parameter that defines how much the angles of each rectangle observation are allowed to deviate from 90°.
Here is another set of rectangles arranged by corner angle deviance from 90°.

Let’s try setting the .quadratureTolerance to 15° and see what we get.

Looks good! We got everything less than 15°. Lowering the tolerance threshold can help prevent false positive hits in real-world images and might also be appropriate for downstream tasks that are sensitive to image skew ( perspective correction may also help).
.minimumConfidence
The .minimumConfidence parameter is a float from 0.0 to 1.0 representing how confident you want the prediction for each rectangle observation to be. In all my experiments with both real-world images and hand drawn examples the subtleties of how the confidence score is calculated remain illusive to me. Based on my knowledge of the algorithm I think Apple is using (generalized Hough transform?), I would have expected the confidence score to gradually decrease in an image like this:

Where each subsequent rectangle has fewer points contributing evidence for its edges. One might then think we could gradually decrease the confidence parameter to pick up all four rectangles, but you can’t. For this image you get the first two rectangles no matter what setting of .minimumConfidence you choose (0.0 to 1.0).
To make matters worse the reported confidence for each observation always seems to be 1.0. For example, take a look at the output after running a request on an image of my keyboard.

Here, I have set .minimumConfidence to 0.0 and all other parameters to values that maximize the number of returned results. This request identified 168 rectangles and every rectangle has a confidence of 1.0. Well that’s not too useful is it? I am not sure if this is a bug or intended behavior.

So at this point you might wonder if this parameter is useful at all, and thankfully it is. Here are the results for the same keyboard image, but this time setting .minimumConfidence to 1.0. Here we only get 130 rectangles and the image does look a little cleaner.
The bottom line here is you may need to experiment with the confidence parameter to get the results you are interested in. Word to the wise though. Do not set this parameter to 0.0 and then try and filter rectangle observations by confidence score…it’s always 1.0!
Summary
Rectangle detection is a fundamental task in computer vision that continues to be relevant in the age of deep learning. When putting together your own vision based apps, consider if rectangle detection might be a useful first step to apply in front of downstream tasks that take more compute. The voyage doesn’t have to end here though. Download the barebones XCode project I used for creating this post and experiment with your own images!
Tips on requests with zero results
make sure you have adjusted at least one of
.minimumAspectRatioor.maximumAspectRatiotry decreasing
.minimumSize, especially if your rectangles are small relative to the total image sizeconsider starting with a wide open search with the following settings:
.maximumObservations= 0.minimumAspectRatio= 0.0.maximumAspectRatio= 1.0.minimumSize= 0.0.quadratureTolerance= 45.0.minimumConfidence= 0.0